
先看段sql
WITH ydz AS ( SELECT zbmc, to_number( value ) value, jldw, nf, yforjd yf FROM ZB_CPCLJC_ZS_TJ WHERE statistic_mark = ‘月度值’ ),
tb AS ( SELECT zbmc, to_number( value ) value, jldw, nf, yforjd yf FROM ZB_CPCLJC_ZS_TJ WHERE statistic_mark = ‘月度同比’ ) SELECT
row_number () over ( partition BY c.nf || c.yf ORDER BY c.tb ) 序号,
c.zbmc 产品名称,
c.cl 产量,
c.dw 单位,
c.tb 同比,
c.nf 年份,
c.yf 月份
FROM
(
SELECT
a.zbmc,
a.value cl,
a.jldw dw,
b.value tb,
a.nf,
a.yf
FROM
ydz a
LEFT JOIN tb b ON a.zbmc = b.zbmc
AND a.nf = b.nf
AND a.yf = b.yf
) c
ORDER BY
6 DESC,
7 DESC,
5 DESC nulls last
partition by类似group by又完全不一样,partition by也用于分组,但计算统计时是以逐条累计的方式计算结果的。
常与row_number() over一起用来计算每个分组的里面单独排序的序号。
with用于提前定义查询结果,然后用该结果再进行其它后续操作。
SQL分析
MYSQL:EXPLAIN
ORACLE:EXPLAIN PLAN FOR
使用PageHelper进行oracle分页时,数据量稍微比较大的时候(百万级),分页查询速度很慢,如下,使用pageHelper分页并没有用到索引。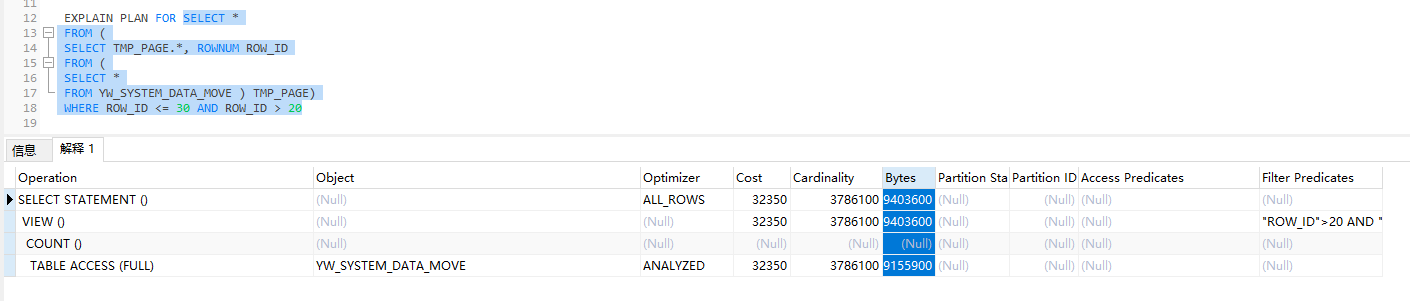
对应的后台分页代码可能就是简单的
PageHelper.startPage(start, size);
//DO SELECT
return new PageInfo(resultList);
考虑到使用索引来查询能更快,于是考虑将查询分页sql改成下面这样。先利用ID的索引来查询分页数据ID,然后利用ID去查询分页的完整数据。但是这样需要自己封装一个分页信息(如共计多少条、分页大小等),需要另外执行sql查询数据库,花费时间需要相加,而且不能很好搭配筛选条件进行查询分页。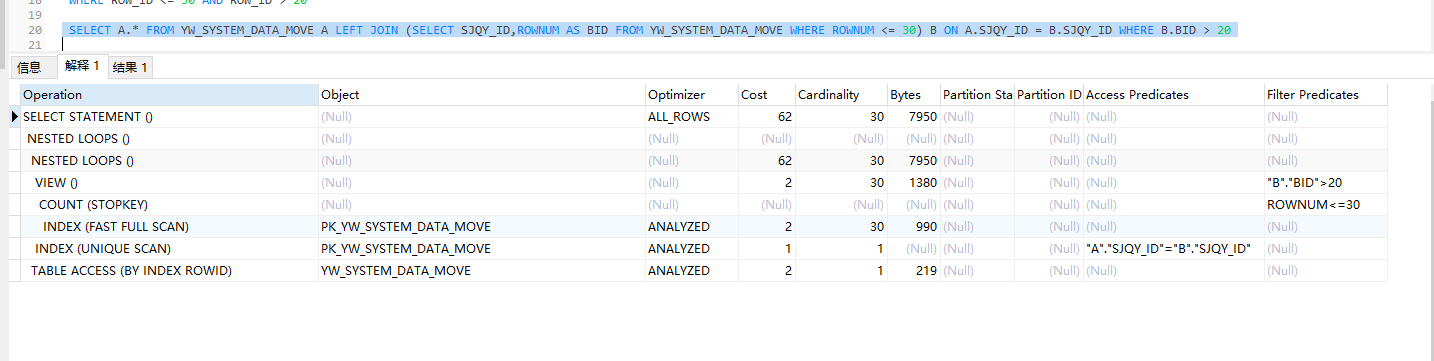
最后选择了折中的方法(不用写太多代码,但速度也不算特快,但比之前分页快多了)
和第一种方式一样,但一开始不查询出所有数据,查询ID的分页信息,PageHelper会自动获取分页信息。
然后利用ID再去查询相应数据(这一步几乎不耗多少时间)。
代码也很简单
PageHelper.startPage(start, size);
//DO SELECT ID => idList
PageInfo page= new PageInfo(resultIdList);
//use idList to select data => dataList
page.setList(dataList);
return page;
这样就做到了百万级数据查询的优化。