B树也为B-树
阶m:一个节点最多的子节点数目
根:根节点,元素个数在1到m-1之间
内节点元素个数:在2到m-1之间
针对m阶高度h的B树,插入一个元素时,首先在B树中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素。
若该节点元素个数小于m-1,直接插入;
若该节点元素个数等于m-1,引起节点分裂;以该节点中间元素为分界,取中间元素(偶数个数,中间两个随机选取)插入到父节点中;
重复上面动作,直到所有节点符合B树的规则;最坏的情况一直分裂到根节点,生成新的根节点,高度增加1。
上面三点为插入动作的核心,接下来以5阶B树为例,详细讲解插入的动作。
首先查找B树中需删除的元素,如果该元素在B树中存在,则将该元素在其结点中进行删除;删除该元素后,首先判断该元素是否有左右孩子结点,如果有,则上移孩子结点中的某相近元素(“左孩子最右边的节点”或“右孩子最左边的节点”)到父节点中,然后是移动之后的情况;如果没有,直接删除。
某结点中元素数目小于(m/2)-1,(m/2)向上取整,则需要看其某相邻兄弟结点是否丰满;
如果丰满(结点中元素个数大于(m/2)-1),则向父节点借一个元素来满足条件;
如果其相邻兄弟都不丰满,即其结点数目等于(m/2)-1,则该结点与其相邻的某一兄弟结点进行“合并”成一个结点;
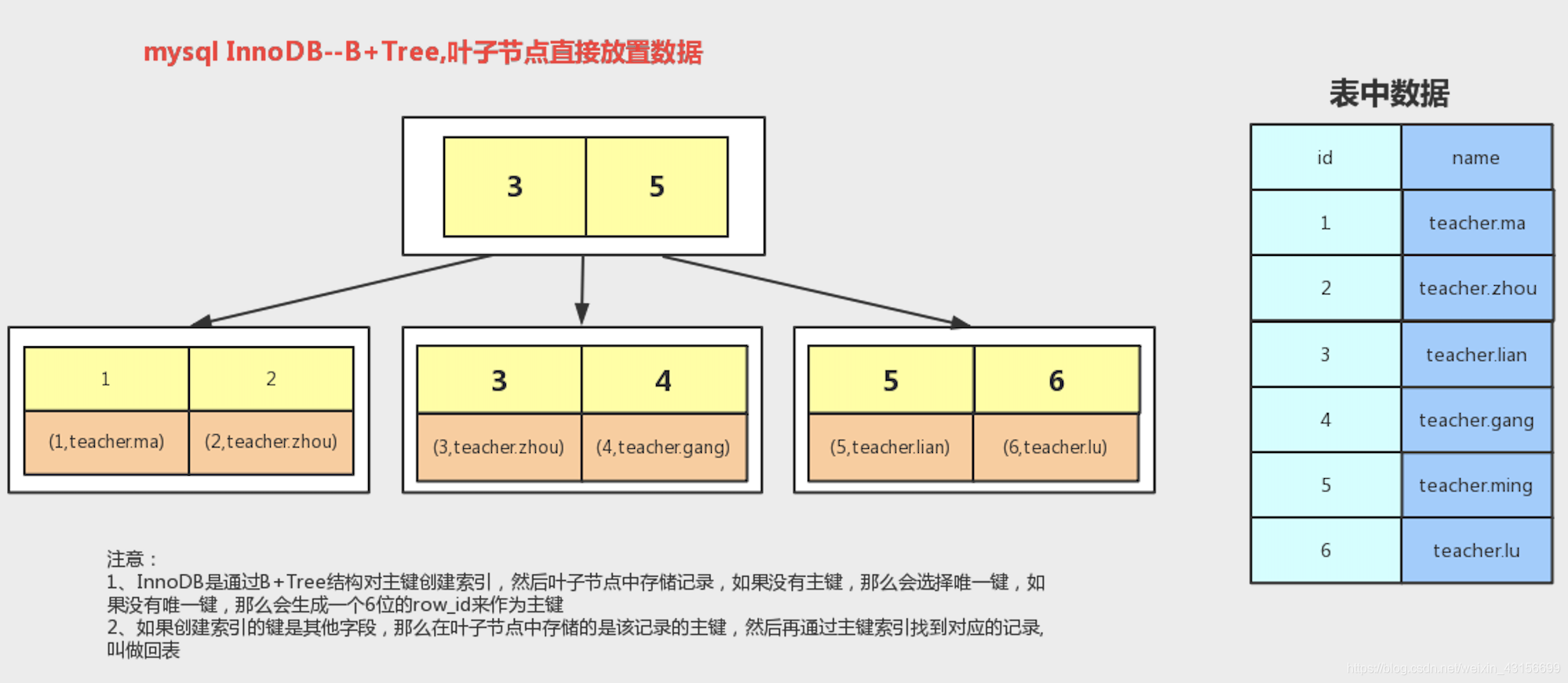
所有数据都存在叶子结点中
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历的效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。